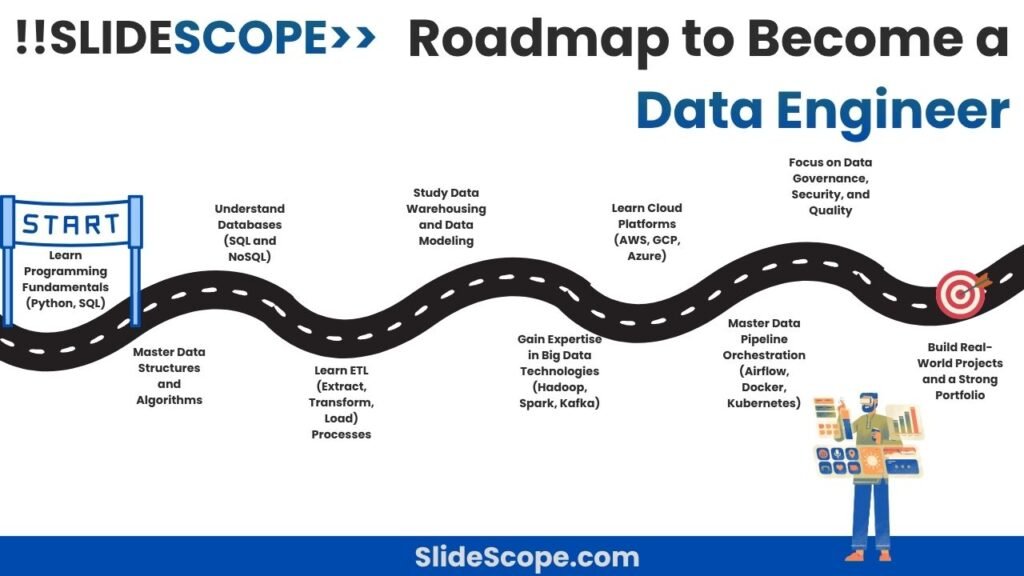
Roadmap to Become a Data Engineer
By Ankit Srivastava
Check our Udemy Profile to view and enroll in courses: https://www.udemy.com/user/d1346146-81ca-4553-8294-5d1b16178406/
Becoming a Data Engineer is one of the most rewarding and technically challenging journeys in the data industry. As businesses rely increasingly on data to drive decisions, the role of a data engineer—someone who builds the systems that collect, store, and process data efficiently—has become indispensable. Having trained professionals in data technologies and worked on data pipelines across multiple industries, I’ve structured this roadmap to guide aspiring data engineers through the learning path, skills, and mindset they need to build a successful career.
1. Build a Strong Foundation in Programming
Every great data engineer starts with solid programming skills. Python is the most preferred language because of its extensive libraries for data manipulation (like Pandas and NumPy) and its integration with big data tools. SQL is equally important — it’s the backbone of data querying, transformations, and database interactions.
You should be comfortable writing complex SQL joins, subqueries, and window functions. Java or Scala can come later if you want to work with distributed systems like Apache Spark.
Tools to learn:
- Python, SQL
- Jupyter Notebook
- VS Code / PyCharm
2. Understand Data Structures and Algorithms
Data engineering is not just about writing queries — it’s about optimizing how data moves through systems. Strong knowledge of data structures (arrays, linked lists, trees, hash maps) and algorithms (sorting, searching, recursion) helps you design efficient ETL processes.
These skills are also essential for interviews and building scalable data pipelines that don’t crash when handling millions of records.
Focus topics:
- Time and space complexity
- Hashing for fast lookups
- Sorting and searching algorithms
- Data flow optimization
3. Learn Databases – SQL and NoSQL
As a data engineer, you’ll manage structured and unstructured data.
Start with Relational Databases (SQL) like MySQL or PostgreSQL, where you learn indexing, normalization, and query optimization.
Then move to NoSQL Databases like MongoDB, Cassandra, or Redis — essential for handling unstructured, large-scale, or real-time data.
Understanding both will help you choose the right database for different business use cases.
Key concepts:
- ACID properties
- Normalization and denormalization
- Indexing and query optimization
- CAP theorem
4. Master ETL (Extract, Transform, Load) Processes
ETL is the heartbeat of data engineering. You need to know how to extract data from multiple sources (APIs, CSVs, SQL servers), clean and transform it, and load it into a data warehouse.
Tools like Apache Airflow, Talend, and Informatica are widely used, but even writing custom ETL scripts in Python (using Pandas or PySpark) is a great skill to start with.
Practice:
- Build a data pipeline that fetches stock data via an API and loads it into PostgreSQL.
- Automate the process using Airflow DAGs.
5. Learn Data Warehousing and Modeling
Data engineers design the systems analysts and scientists use to access data easily.
You must understand how data warehouses like Snowflake, Google BigQuery, and Amazon Redshift store and manage analytical data.
Learn data modeling techniques like Star Schema and Snowflake Schema, and how to design fact and dimension tables for fast analytics.
Key skills:
- Dimensional modeling
- OLTP vs OLAP
- Data warehouse architecture
- Partitioning and indexing
6. Gain Expertise in Big Data Technologies
When datasets grow beyond the capabilities of traditional databases, Big Data technologies come into play.
Learn about the Hadoop ecosystem—HDFS (storage), YARN (resource management), and MapReduce (processing).
Then, move to Apache Spark, which has become the industry standard for distributed data processing because of its speed and versatility.
You should also understand Kafka for real-time data streaming.
Important tools:
- Hadoop
- Spark (PySpark preferred)
- Apache Kafka
- Hive / Pig
7. Learn Cloud Platforms and Data Services
Today, most organizations use cloud-based data architectures. Understanding AWS, Google Cloud (GCP), or Microsoft Azure is essential.
Each platform offers specialized services for data engineers — for example:
- AWS Glue (serverless ETL), S3 (data storage), and Redshift (data warehouse)
- GCP BigQuery and Dataflow
- Azure Synapse Analytics and Data Factory
Learn how to deploy pipelines, manage cloud storage, and ensure security using IAM (Identity and Access Management).
8. Master Data Pipeline Orchestration and Workflow Automation
A professional data engineer doesn’t just build pipelines — they automate, monitor, and scale them.
Apache Airflow, Luigi, and Prefect are top tools for workflow orchestration.
These tools help you define complex pipelines with multiple dependencies, schedule them, and handle failures automatically.
Learning Docker and Kubernetes will also help you deploy and scale pipelines efficiently in containerized environments.
Key topics:
- DAGs (Directed Acyclic Graphs)
- Job scheduling
- Containerization with Docker
- Orchestration with Kubernetes
9. Strengthen Data Governance, Security, and Quality Skills
Data isn’t useful unless it’s accurate, secure, and compliant.
A good data engineer must implement data validation, error handling, and audit logging mechanisms.
You should also know about data privacy regulations like GDPR and HIPAA, and encryption techniques for secure data transfer.
This ensures your pipelines are not just functional, but reliable and compliant.
Key focus:
- Data validation frameworks (e.g., Great Expectations)
- Access control and data masking
- Logging and monitoring tools (ELK stack, Prometheus, Grafana)
10. Work on Real Projects and Build a Portfolio
Finally, practice is everything.
Start building projects that showcase your skills — such as a real-time sales analytics pipeline, a COVID-19 data warehouse, or an IoT data stream using Kafka.
Deploy these projects on GitHub or a personal website. Employers value real-world, end-to-end pipeline experience more than certifications.
Project ideas:
- ETL pipeline from APIs to Snowflake
- Spark job analyzing large social media datasets
- Real-time dashboard using Kafka and Power BI
Additional Tips from My Experience
- Learn Git and version control early; it’s crucial for collaboration.
- Stay updated with new frameworks — data engineering evolves rapidly.
- Learn basic DevOps and CI/CD concepts to automate deployments.
- Collaborate with data analysts and data scientists to understand how your pipelines support their goals.
Final Thoughts
The path to becoming a data engineer is a mix of technical mastery and problem-solving creativity. You’ll evolve from writing small ETL scripts to designing complex, distributed data systems that empower business intelligence and machine learning models.
As someone who has trained students and professionals at Slidescope Institute, I’ve seen that the best data engineers are those who constantly experiment, automate, and optimize. They understand both the technical and business side of data — bridging the gap between raw information and valuable insights.
If you’re ready to start this journey, begin by mastering Python, SQL, and cloud platforms, then gradually move toward advanced tools like Spark, Airflow, and Kafka.
Want a structured path with hands-on guidance?
Learn Python, SQL, Big Data, and Cloud Data Engineering with our Data Engineering Certification Program at Slidescope Institute — where real-world projects prepare you for top roles in data-driven companies. Contact Us
